
Overview
Knowledge Search uses Retrieval Augmented Generation (RAG) to provide intelligent, semantic search across your SharePoint document libraries. Unlike traditional keyword search, Knowledge Search understands the meaning of your questions and finds relevant information even when exact keywords don’t match.Semantic Search
Understands intent, not just keywords
Multi-Corpus Query
Search multiple document collections simultaneously
Source Attribution
Every answer includes citations to source documents
Auto-Sync
Automatically updates when documents change
What is a Corpus?
A corpus is a collection of documents from a SharePoint site or document library that has been:- Embedded (converted to vector representations)
- Indexed for semantic search
- Made searchable through AVA
Example Corpora
- Legal
- HR
- Support
- Sales
Contracts Corpus
- Source: Legal/Contracts SharePoint library
- 350 vendor and customer contracts
- Auto-sync: ON
- Field extraction: Company Name, Contract Type, Effective Date, Value
Creating a Corpus
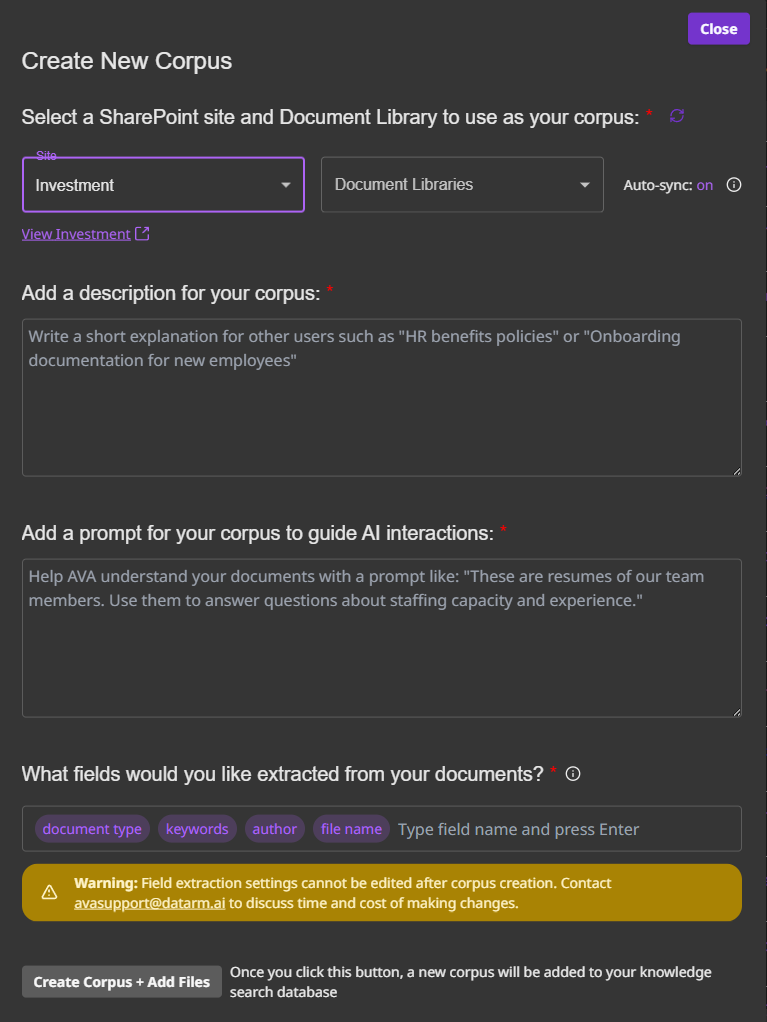
Select SharePoint Site
- Choose from dropdown of available sites
- Must have read access to the site
- Can preview site contents
Select Document Library
- Choose specific library within site
- See document count preview
- Supported types: PDF, Word, Excel, PowerPoint, text
Add Description
Write clear description:
“Contains all vendor contracts from 2020-present.
Use for contract term searches, renewal dates, and
clause analysis.”Good descriptions help users know when to use this corpus.
Configure Auto-Sync
Auto-Sync ON: AVA periodically checks SharePoint for: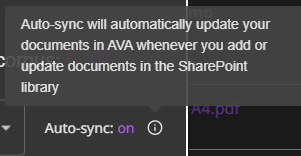
- New documents (added automatically)
- Modified documents (re-embedded)
- Deleted documents (removed from corpus)
Set Field Extraction (Optional)
Extract custom fields from documents for enhanced filtering:Common fields:
- document_type: Contract, Policy, Guide
- department: Sales, Legal, Engineering
- date: Effective date, creation date
- author: Document creator
- company: Customer or vendor name
- keywords: Custom tags
Using Knowledge Search
Basic Search
Select Corpus
Click ”@ Connected Data” button, choose corpus from dropdownExample: Select “@Contracts Demo”Tip: You can select multiple corpora to search simultaneously
Ask Question
Type your question in natural language:Examples:
- “Find contracts with termination for convenience clauses”
- “What are the indemnification terms in customer contracts?”
- “Show me all contracts expiring in Q1 2025”
Review Results
AVA returns:
- Answer: AI-generated response synthesizing relevant information
- Sources: Links to specific documents with relevance scores
- Excerpts: Relevant passages highlighted
Advanced Search Techniques
Multi-Corpus Search
Multi-Corpus Search
Search across multiple knowledge bases simultaneously:Select multiple corpora:
- @Contracts Demo
- @Vendor Agreements
- @MSAs (Master Service Agreements)
Field Filtering
Field Filtering
If corpus has field extraction configured:Query: “Find contracts where document_type=‘MSA’ and company contains ‘Tech’”AVA filters documents matching criteria before searching contentUse Case: Narrow search to specific document categories
Date Range Queries
Date Range Queries
Query: “Show contracts signed in 2024”AVA understands temporal queries and filters accordinglyMore examples:
- “Policies updated in the last 6 months”
- “Guides created this year”
- “Contracts expiring next quarter”
Comparison Queries
Comparison Queries
Query: “Compare payment terms in Microsoft contract vs Salesforce contract”AVA retrieves both documents and provides side-by-side comparisonMore examples:
- “How does our current PTO policy differ from the 2020 version?”
- “Compare indemnification clauses across top 5 contracts”
Extraction Queries
Extraction Queries
Query: “Create a table of all contracts with columns: Company, Value, Expiration Date, Auto-Renewal”AVA extracts structured data from multiple documentsExport: Can export table to ExcelUse Case: Data extraction and analysis
Managing Corpora
Corpus Dashboard
View all your corpora and manage embedded files: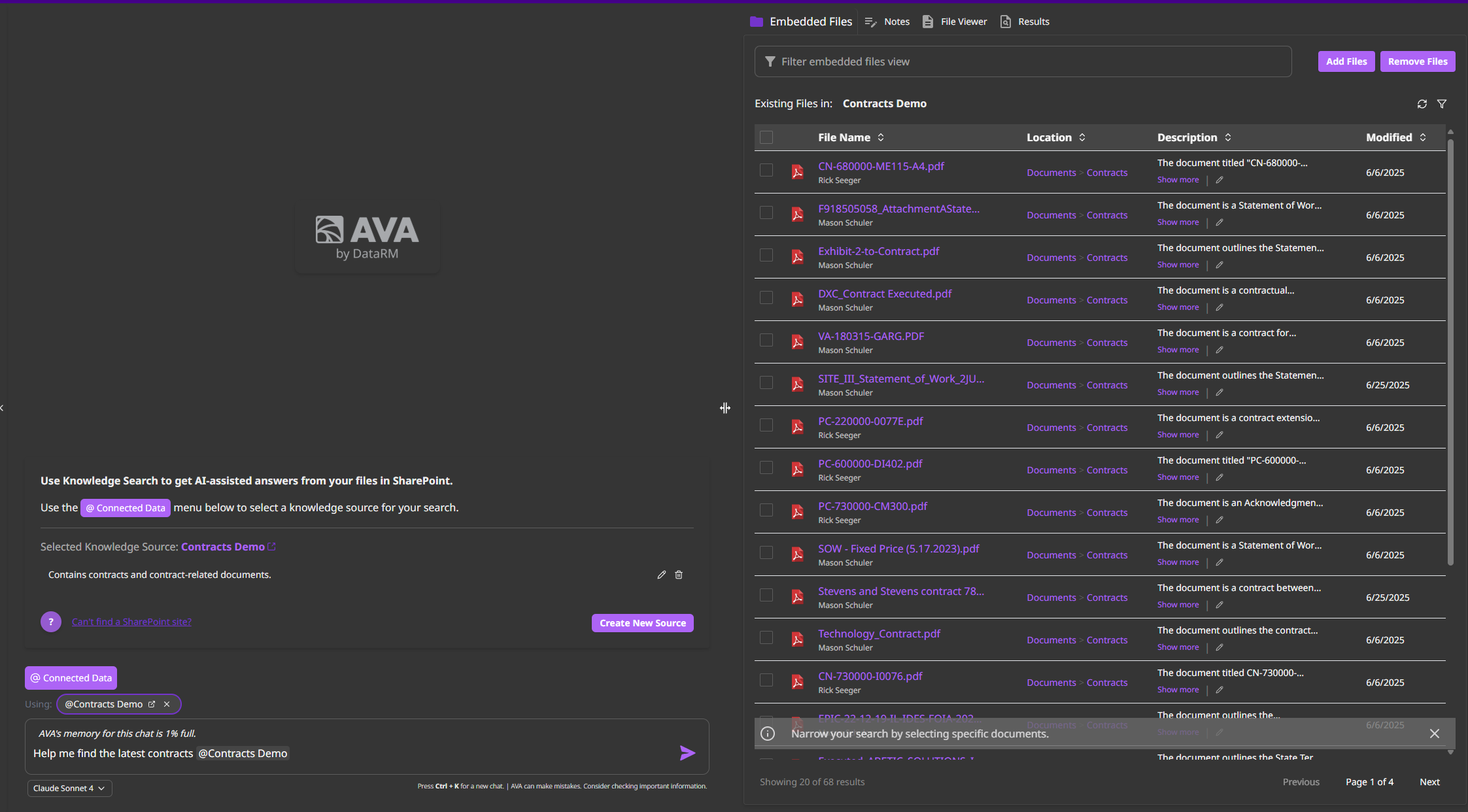
Corpus List
- All corpora you own or have access to
- Document count per corpus
- Last sync timestamp
- Storage size
Search Analytics
- Most searched corpora
- Common queries
- User adoption metrics
- Performance stats
Embedded Files View
- See all documents in corpus
- Individual file status
- Add or remove specific files
- Re-embed modified documents
Sharing Settings
- Who has access
- Permission levels
- Share with teams or individuals
Corpus Maintenance
- Adding Documents
- Removing Documents
- Re-Embedding
- Corpus Settings
With Auto-Sync ON:
- Add documents to SharePoint library
- AVA automatically detects and embeds
- Typically within 1 hour
- Navigate to corpus settings
- Click “Add Files” button
- Select files from SharePoint
- Click “Embed Files”
- Choose specific documents to add
- Useful for selective corpus building
How Knowledge Search Works (Technical)
The RAG Pipeline
Document Ingestion
When you create a corpus:
- AVA connects to SharePoint using your delegated permissions
- Downloads documents you have access to
- Extracts text content from each file
- Chunks documents into manageable segments (~500 tokens each)
Embedding Generation
For each chunk:
- Sent to embedding model (text-embedding-ada-002)
- Converted to vector representation (1536 dimensions)
- Vector stored in PostgreSQL with pgVector extension
- Metadata stored: filename, page number, chunk position
Search Query Processing
When you search:
- Your question is converted to vector embedding
- pgVector performs similarity search across all embedded chunks
- Top K most relevant chunks retrieved (typically 5-10)
- Relevance scores calculated
Why This Works Better Than Keyword Search
| Keyword Search | Knowledge Search (RAG) |
|---|---|
| Exact word matches only | Understands meaning and intent |
| Misses synonyms and variations | Finds semantically similar content |
| No context understanding | Considers document context |
| Returns documents, not answers | Generates specific answers |
| Manual review of results | AI-synthesized responses |
| No source attribution | Automatic citations |
- Might miss documents that say “remote work” or “telecommute”
- Returns list of potentially relevant documents
- You read through each to find answer
- Finds documents about remote work, telecommuting, work-from-home
- Returns: “According to the Remote Work Policy (updated Jan 2024), employees can work from home up to 3 days per week with manager approval…”
- Includes link to exact policy document
Use Cases by Department
Legal Department
Contract Management
Contract Management
Corpus: All contracts (vendor, customer, partner)Common Searches:
- “Find all contracts with limitation of liability caps under $1M”
- “Which contracts allow assignment to affiliates?”
- “Show me indemnification obligations in SaaS contracts”
- “Create table of all contract renewal dates in next 90 days”
Legal Research
Legal Research
Corpus: Internal legal memos, case summaries, precedentsCommon Searches:
- “Have we dealt with this issue before?”
- “Find similar disputes and their resolutions”
- “What was Legal’s opinion on X in the past?”
Compliance Documentation
Compliance Documentation
Corpus: Regulatory documents, compliance policiesCommon Searches:
- “What are GDPR requirements for data retention?”
- “Show me all data privacy policies”
- “What’s required for SOC2 compliance?”
HR Department
Policy Questions
Corpus: Employee handbook, HR policiesUse: Answer employee questions instantly
“What’s the parental leave policy?”
“How do I request PTO?”
Benefits Info
Corpus: Benefits guides, provider documentsUse: Help employees understand benefits
“What dental plans are available?”
“How does HSA work?”
Onboarding
Corpus: Onboarding materials, training docsUse: New hire questions
“What systems do I need access to?”
“What’s the dress code?”
Procedures
Corpus: HR process documentationUse: HR team reference
“How do I process a termination?”
“What’s the promotion approval process?”
IT/Support
- Troubleshooting
- How-To Guides
- System Documentation
Corpus: Technical support documentationSearches:
- “How to fix login timeout errors?”
- “Steps to reset user password”
- “Troubleshoot VPN connection issues”
Sales & Marketing
Competitive Intelligence
Corpus: Competitive research, battle cardsUse: “How do we compare to Competitor X on feature Y?”
Past Proposals
Corpus: Winning proposals and case studiesUse: “Find proposals for healthcare industry customers”
Product Documentation
Corpus: Product specs, feature descriptionsUse: “What are the key features of Product X?”
Best Practices
Organize by Purpose
Organize by Purpose
Create separate corpora for different use cases:✅ Good:
- “Vendor Contracts” corpus
- “Customer Contracts” corpus
- “NDAs” corpus
- Single “All Contracts” corpus with everything
Write Clear Descriptions
Write Clear Descriptions
Help users understand when to use each corpus:✅ Good:
“Contains all active vendor contracts from 2022-present.
Use for: payment terms, renewal dates, SLA requirements.
Auto-synced daily.”❌ Avoid:
“Vendor stuff”Why: Users find the right corpus faster
Enable Auto-Sync for Active Libraries
Enable Auto-Sync for Active Libraries
For document libraries that change frequently:
- Policy documents
- Active contracts
- Current product documentation
- Historical/archived documents
- Reference libraries that don’t change
Use Field Extraction
Use Field Extraction
Plan field extraction before creating corpus:Useful fields:
- Document category/type
- Date (effective, expiration, creation)
- Company/customer name
- Department/owner
- Status (active, expired, draft)
Test with Questions
Test with Questions
After creating corpus, test with common questions:
- Ask typical user questions
- Verify relevant documents are returned
- Check if answers are accurate
- Refine corpus if needed
Performance & Limits
Document Limits
- Max documents per corpus: 10,000
- Max file size: 50MB
- Supported types: PDF, Word, Excel, PowerPoint, TXT
Search Performance
- Vector search: Less than 1 second
- AI response generation: 3-8 seconds
- Typical total: 5-10 seconds per query
Storage
- Vectors stored in PostgreSQL with pgVector
- Original files remain in SharePoint
- Corpus metadata and embeddings: ~1MB per 100 pages
Concurrent Users
- No hard limit on concurrent searches
- Auto-scales with Azure Container Apps
- Performance degrades gracefully under load
Troubleshooting
- No Results
- Wrong Results
- Slow Processing
- Auto-Sync Issues
Problem: Search returns no relevant resultsSolutions:
- Try rephrasing question
- Check if documents are actually embedded (view embedded files)
- Verify you have access to source SharePoint library
- Try broader search terms
- Check if corpus needs re-embedding (if documents updated)
Next Steps
Create Your First Corpus
Step-by-step guide to creating and using a corpus
Advanced Techniques
Learn field extraction, multi-corpus search, and more
Use Case Examples
See how teams use Knowledge Search
Best Practices
Tips for optimal corpus management